fork & join 프레임워크
: 하나의 작업을 작은 단위로 나눠서 여러 쓰레드가 동시에 처리하는 것을 쉽게 만들어주는 프레임워크이다.
jdk1.7부터 추가 되었다.
* RecursiveAction과 RecursiveTask 클래스
사용하려면 수행할 작업에 따라 RecursiveAction과 RecursiveTask, 두 클래스 중에서 하나를 상속받아 구현해야한다.
| RecursiveAction | 반환값이 없는 작업을 구현할 때 사용 |
| RecursiveTask | 반환값이 있는 작업을 구현할 때 사용 |
// 두 클래스 모두 compute()라는 추상 메서드를 가지고 있는데, 상속을 통해 이 메서드를 구현하면 된다.
public abstract class RecursiveAction extends ForkJoinTask<Void> {
...
protected abstract void compute(); // 상속을 통해 이 메서드를 구현해야함.
...
}
public abstract class RecursiveTask<V> extends ForkJoinTask<Void> {
...
protected abstract V compute(); // 상속을 통해 이 메서드를 구현해야함.
...
}compute()
: compute는 작업을 더이상 나눌 수 없을 때 까지 쪼개어서 수행하는 것이다.
compute()가 처음 호출되면, 작업의 길이를 반으로 나눠서 한 쪽에는 fork()를 호출하여 작업 큐에 저장한다.
하나의 쓰레드는 compute()를 재귀호출하면서 작업을 계속 반으로 나누고, 다른 쓰레드는 fork()에 의해 작업큐에 추가된 작업을 수행한다.
compute()의 구조는 일반적인 재귀호출 메서드와 동일하다.
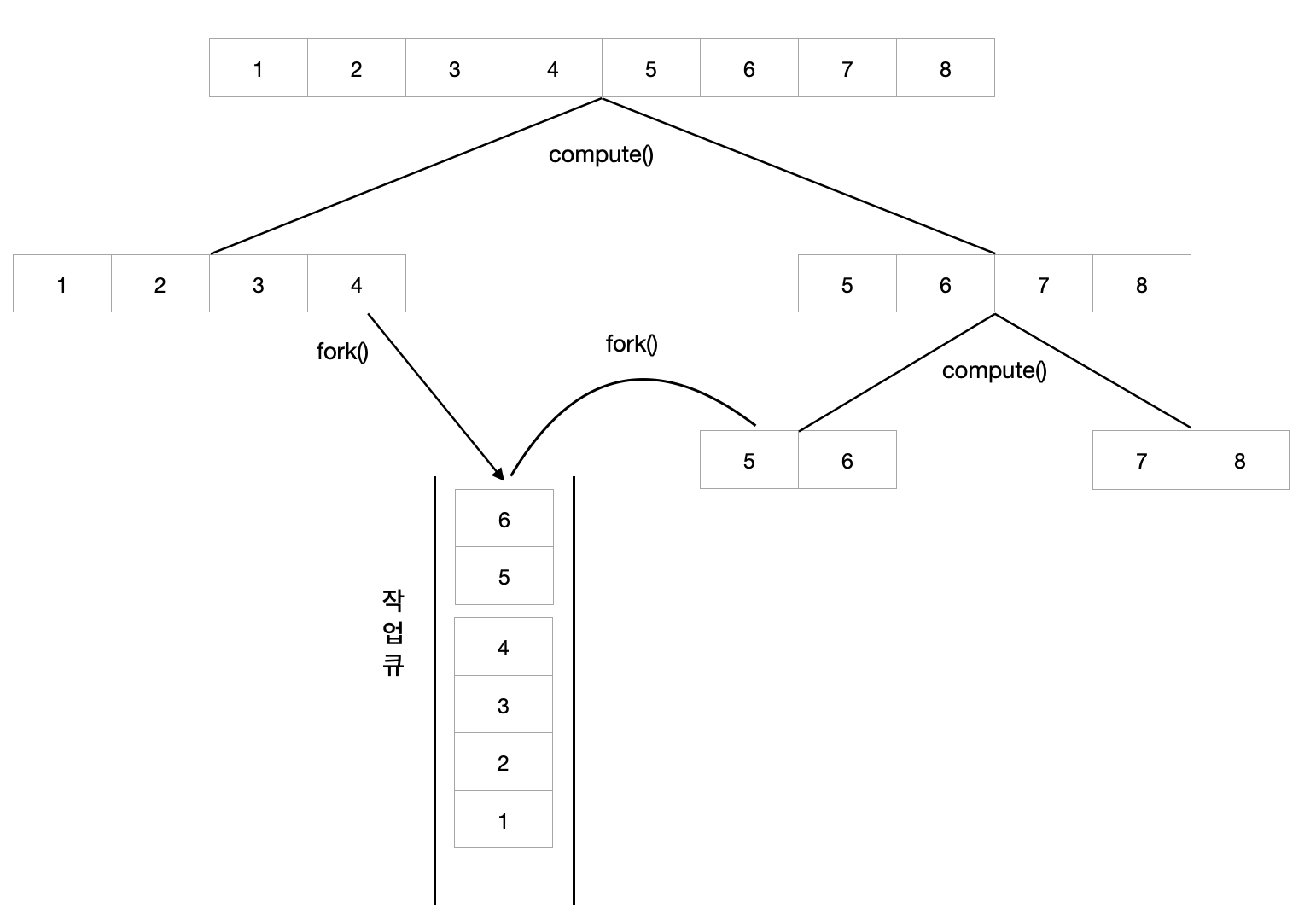
fork()와 join() 활용 방법
| 메서드 | 설명 |
| fork() | 해당 작업을 쓰레드 풀의 작업 큐에 넣는다. 작업 큐에 들어간 작업은 더 이상 나눌 수 없을 때까지 나뉜다. 비동기 메서드라서 호출만 할 뿐 결과를 기다리지 않는다. |
| join() | 해당 작업의 수행이 끝날 때 까지 기다렸다가, 수행이 끝나면 그 결과를 반환한다. 동기메서드이다. |
* 1~ 100000000까지 더하는 예시
* fork & join 프레임워크 수행단계는 다음과 같다.
쓰레드 풀을 생성 -> 수행할 작업을 생성 -> invoke()를 호출하여 작업 시작
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinEx1 {
static final ForkJoinPool pool = new ForkJoinPool(); // 쓰레드 풀을 생성
//
public static void main(String[] args) {
long from = 1L, to = 100_000_000L;
SumTask task = new SumTask(from, to); // 수행할 작업을 생성
long result = pool.invoke(task); // invoke()를 호출해서 작업을 시작
System.out.println(result); // 5000000050000000 출력
}
static class SumTask extends RecursiveTask<Long>{
long from, to;
SumTask(long from, long to){
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
long size = to - from + 1; // from <= i < to
if(size <= 5) return sum(); // 더할 숫자가 5개 이하면 숫자의 합을 반환
long half = (from+to)/2;
// 범위를 반으로 나눠서 두 개의 작업을 생성
SumTask leftSum = new SumTask(from,half);
SumTask rightSum = new SumTask(half+1,to);
leftSum.fork();
return rightSum.compute() + leftSum.join();
}
long sum(){
long tmp = 0L;
for(long i=from; i <= to; i++){
tmp += i;
}
return tmp;
}
}
}** 멀티쓰레드로 처리한 것이 항상 빠르지 않기 때문에 반드시 테스트 해보고 이득이 있을 때만, 멀티 쓰레드로 처리 해야한다.
※ ForkJoinPool
fork & join프레임워크에서 제공하는 쓰레드 풀이다.
지정된 수의 쓰레드를 생성하여 미리 만들어 놓고 반복해서 재사용할 수 있게한다.
기본적으로 쓰레드 풀은 코어의 개수와 동일한 개수의 쓰레드를 생성한다.
쓰레드를 반복해서 생성하지 않아도 된다는 장점과 너무 많은 쓰레드가 생성되어서 성능이 저하되는 것을 막아준다는 장점이 있다.
쓰레드 풀은 쓰레드가 수행해야하는 작업이 담긴 큐를 제공하며, 각 쓰레드는 자신의 작업큐에 담긴 작업을 순서대로 처리한다.
728x90
반응형
'개발 공부 > Java & Spring' 카테고리의 다른 글
| 23. 스트림 - collect() (0) | 2023.03.26 |
|---|---|
| 22. 스트림의 최종연산 (0) | 2023.03.26 |
| 20. volatile (0) | 2023.03.09 |
| 19. 쓰레드의 동기화 (0) | 2023.03.09 |
| 18. 애너테이션(annotation) (0) | 2023.02.15 |